目录
从前端开发看面向未来的敏捷学习法
注:本文第一版我首发于我的GitChat,这一版我在原有基础上更新并增加了一些章节,后请 Shize Zhou 整理并重新排版,在这里也发布一下。本文以前端开发为载体讲解在新形势下的程序员的学习方法,因自己水平有限,内容接受大家批评,欢迎读者和我深入讨论。本文还发布过个人的 (jianshuhttp://www.jianshu.com/p/fd7055705c62)。
大纲
- 选题背景
- 敏捷学习法
- 知识迁移
- 信息获取与筛选
- 新形势下的阅读方式
- 社区化学习
- 工具\&实验田
- 时间管理
- 画图与做题
- 总结
1.0 选题背景
在纠结选题时候,我一直在思考分享什么知识比较好。平时在工作中确实有许多经验和技术积累可以分享,但我发现这些技术在互联网上或多或少都有相应资料,自己平时遇到各种问题也是去探寻的。于是我觉得不如聊聊面向未来的学习方法,有时候具体讲一个知识点不如告诉你如何自己在资料海洋中自我敏捷学习。
每个开发者都是从小白走过来的,这条路非常坎坷。有的人花了较少时间就达到了架构师级别并且带领小团队有序开发,有的开发者则花了5、6年时间还在基础岗折腾。抛开个人努力程度看,学习方法也是至关重要的。说到学习方法,从小到大我们学习过很多知识,可真正在工作中用到的却是很小的子集,留下的是学习知识的能力。
目前行业趋势迫使大家不断跟进新技术,需要较高学习能力的人。我们研发 WebIDE 时,团队并没有所谓的 IDE 工程师,国内同类产品就是空白,一切只能靠我们上海几个人各种摸索学习在短时间内做出产品。产品很出色但是过程却是痛苦的,新问题新难点不断涌现。这时除了努力更需要的是解决问题的能力。如果你能拥有这样的能力,即使你不会某个具体技术点,那并不重要。因为你可以短时间学会,并同时夯实基础,这才是面向未来的人才。
在技术瞬息万变的今天,原来那些只靠学历、人脉、经验升职已经过时了,要想保持自己的职场竞争力,练好一件本事就够了,那就是学习敏捷力。——美国著名企业高管教练,瓦尔库。
我以前端开发为例,社区技术派别已达到了百家争鸣阶段,众多公司推出了自己的最佳实践以及相应的开源库,学校、培训班、出版社尽力的跟随。在这种情况下,很多朋友很困惑,按照传统一般的学习方法,似乎很难应对。选资料或书籍就是一个大难题,读完别人又告诉此版本已升级或者书中有很多错误,甚至工作中已经不再使用了。再者,平实工作任务很紧,没时间让你慢慢啃。还有很多知识要你同时去学。
这时候很多人开始烦躁、抵触,迷茫,怀疑技术,怀疑自己。而恰恰这时候需要的是耐心,走一点,停下来,仔细思考自己的学习方法是不是需要调整一下了。以上的思考过程,让我明白第一次 GitChat 的分享内容,以前端开发为载体和大家聊聊面向未来的社区化敏捷学习方法。必须要说明的是,这块知识量很多,本次分享只能从面上给大家介绍无法太细致。
2.0 敏捷学习法
敏捷学习方法并没有专业的文献资料做背书,我只是结合自身理解和大家分享,受限于自身水平,并不一定是对的,只望给大家有参考意义。本节从基本的理论、知识树以及两个案例开始。
2.1 理论
敏捷学习的核心是敏捷的通过外部刺激更新自己的知识树。
所谓的外部刺激主要包括被动解决各类问题以及主动研究各类课题。解决新问题时,利用自己已积累的所有相关知识判断可能的最优解决方法并拿它排序。其后对解决方案做拆解得出一些知识关键词,逐条快速通过知识获取途径得到相关资料,迅速实验田验证,过程中需要实时更新自己的知识树,后期不断完善整理知识树,成为新的积累,便于之后新的问题突破。主动研究课题时,则通过阅读各类资料迅速整理知识点,更新知识树,重建新知识与老知识的关系链,弄清楚每一个知识之间的联系。
2.2 知识树基本概念
我们把自己的知识想象成是一颗带有关系箭头的树(思维导图)。如图:
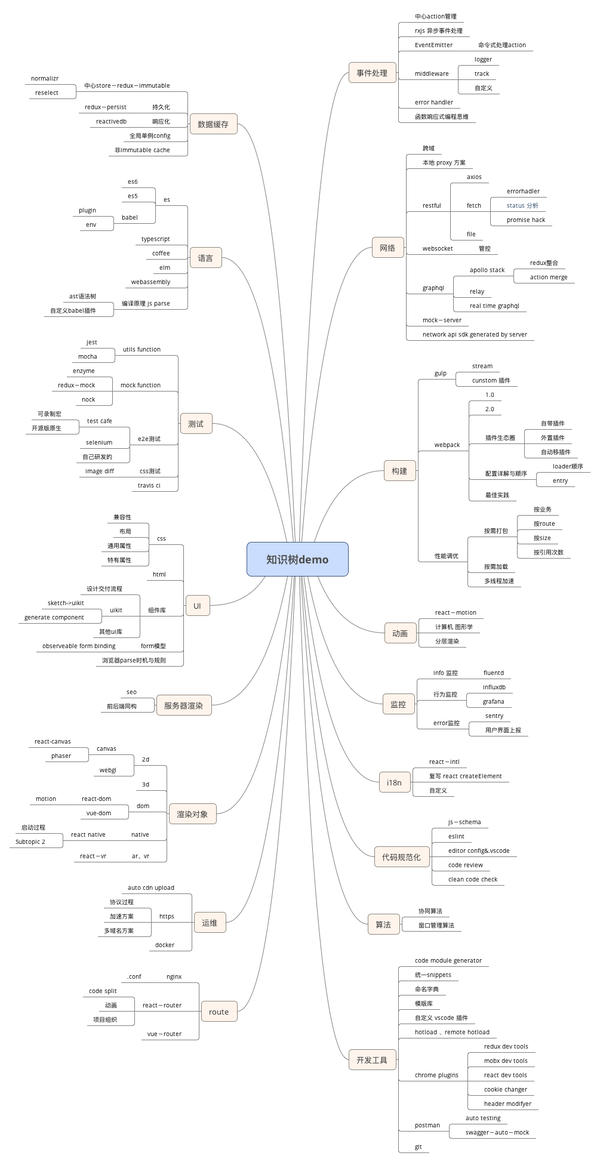
思维导图demo
知识关系图
此图只是 demo,每个知识结点都有自己的关联和上下文。我们可以给每个子模块添加颜色,深浅代表我们的对他的记忆程度,越实则使用越频繁,记忆也越深,越虚则越淡。甚至可能只是一个软链接在这里占位,遇到这个问题知道怎么搜索怎么查,但是不一定深刻理解。我们每天做各类项目和平时阅读交流的过程中,只要遇到新的知识,就应该先他挂到我们的知识树上,成为一颗虚树,而后继续整理,填充知识关系与知识深度使树更完善。这里所描述的知识树是一个抽象的概念,具体表现形式大家可以有自己的发挥。我一般使用思维导图,复杂的知识需要多个 sheet 来表达,并做好关联工作。
下面结合前端开发工作中实际的解决问题与主动学习两个案例让大家热热身。
2.3 敏捷解决问题案例
本节介绍自己曾经解决过的一个问题,告诉大家我的思考方式和学习方式。
2.3.1 问题分析
Issue: 解决一个 RN 项目开机经常直接闪退的问题。
直接静态观察代码,并看不出什么问题来,简单的 debug 也反映不出问题。假定我是一个 RN 初学者,但是 KPI 要求我迅速完成工作。
我通过其他编程经验告诉我,对闪退和性能的问题,需要对开机过程每一步启动过程做一个分析,打合适断点观测,看看哪一步闪退了,确定问题。而后则方案无非就是
- Catch 相应的 error,不能让他影响整个 APP
- 解决相应业务的问题。
2.3.2 知识拆解
我把问题第一步监测大点拆解为以下三个问题。
- RN 开启到首页渲染的关键帧(关键重要的可测结点)。
- 监测与表达。
- 监测内容。
2.3.2.1 第一个问题
先从自己的知识树去找,假设我对 RN 的启动顺序,只停留在“先加载需要用的资源,然后调用 JS 逻辑”的层面。为了解决问题,必须获取这方面知识,在知识树上建立虚树。技术术语主要就是: React native start order, React native debug 之类。从 Google 搜索得到了一些网页信息,从 Stack Overflow 也得到了一些相关问题。经过整理然后我得出了解决方案,断点应该打在 Native 启动入口,JS-Bridge,JS 入口点,JS 初始化操作(redux store 初始化)、JS view mount 的起点等...同时我把刚才的几篇文章 link 和内容做了一个速记,补充在这颗虚树中,提醒我之后可以完善它。关于获取信息的方法与筛选在之后的章节会详细讲解。
2.3.2.2 第二个问题
基本上思路就是把断点处的各种监测数据 dump 到统一的 dashboard 中。我联想到在其他编程体验中,我也许会用自带的断点工具,或者 console.log 把相关信息打在控制台。当然也可能会丢给 data collector server 统一观测,这取决于不同的业务场景。
在这个案例中,JS 和两个 native 以及中间的一些库的 service 并不在一个 scope,很难能跨服务的跟踪,追查哪一步出了什么问题导致启动慢而容易 crash。于是就用了做微服务监测的知识点,用 fluentd 做一个 log center,它能把 logger 汇聚到一起展现出来。
2.3.2.3 第三个问题
回到一开始的需求,我需要解决启动慢且容易闪退的问题。需要检测两个主要信息点,一个是 time duration;一个是 health check。所以每一层断点需要做的就是给我反馈出耗时(当前时间与第一个断点时间差)、当前健康情况。
2.3.3 实验
我们必须迅速做实验判断此方案的可行性,本案例中实验环境的搭建很简单。fluentd 用 Docker 版本地先布,代码库则建一个 multiple worktree,在 fake 节点上做实验。先测几个最重要的断点,最快速度判断此方案是否可行,并初步缩小范围。经过检验,方案可行,在 native 层的 health 情况正常,时间在允许范围内。接下来只需要测试 JS 部分即可。
2.3.4 实施
经过实验,我们确定这个监测方案是可行的,接下来按照流程一步一步实施。实施过程和之前一样。实施的结论:最终我们发现,redux-persist-store 这个库耗时过长并有一定几率崩溃。
2.3.5 确诊问题
我们看到的监测结果类似医院的化验结果,确诊需要拿结果结合经验以及别人的实践找出原因,目的是为了寻找测试用例。根据这库功能猜可能是缓存数据没存对,导致一进来的时候就奔溃了。此时关键词描述变成了 redux-persist-store crash 问题,看了一圈别人的 issue 之后,更加坚定这个想法。这时候需要寻找必现问题的测试用例。ADB 进安卓系统,发现 persist store 在本地存的是文件。这时候我通过对他的增、删、改等手段,观察我们的 log 与 APP 情况。发现当数据结构不一致时它必然崩溃,所以猜想被印证是对的。此时立马更新我的知识树,并加深了我对 redux-persist 的印象。
2.3.6 对症下药
这个步骤需要对症下药,此时症状能表达的关键词更加明确:
- 对这个错误类型做 catch
- Persist store 需要调整数据缓存中间过程,不应该留有错误数据。
这个问题先看看社区是怎么做的,于是继续进入资料查找模式,找到此库有 custom transform 的 API 可以让我处理 incomming 和 outcomming 的流,于是我可以在那个 scope 去做 data check。至于 check 这个知识点,根据以前编程知识我们很容易想到结构验证,和数据筛选。这里继续用敏捷学习法,学到结构验证可用 JS-Schema 做,数据筛选则直接写规则 filter。Schema 的规则根据实际数据情况定,filter 规则根据做 Code split 概念的影响,应该是有按需缓存,按使用比例缓存,按 size 缓存的策略。对 error handler 这个知识点,我们很容易想到 try, catch, filter error type 这些词语,但是这里是 native 报错而出问题的库在 JS 里,RN 肯定做了一些事。对着这个查询 RN 的 error 机制,获取到社区推荐的 ErrorUtil 全局对象 catch fatal error 的方式,于是下一步依然事实验与实践,发现起效。最后则把刚才的代码配上前面的测试用例,写成测试安心交付。同时把这个问题研究结果子树,render 到自己的知识树上,并把知识相应的关联体系补上,比如以前这块知识只是 redux-persist 是解决 store 数据持久化的,为了下一次打开还原现场。这次新增对持久化的数据做 transform 以解决什么数据需要持久化,多少数据需要持久化,存储校验,异常处理等等。
2.3.7 总结
我们在解决问题的思维过程应该和 CI 流程一样,一步一步非常清晰。不断的迁移知识分析问题,不断拆解问题到更小的原子问题,不断对每个问题深化关键词,不断获取此关键词的信息并从信息获取更准确的关键词,不断抽象解决方案模型做实验验证可行性弄清楚实现机制,每一步则注意 Single responsibility principle 的应用,最后过程中的知识增长需要把 diff 记录进自己的知识树。
2.4 敏捷主动学习案例
本节结合敏捷学习介绍主动学习 Redux 的案例,由于这里篇幅会太长,只能浓缩介绍关键部分。如果让你快速学会 Redux 并着手重构曾经的项目,我们会怎么做?把 Redux 书和相关背景都读一遍恐怕是来不及的,由于知识是有背景和上下文的,再讲这个案例时我只能假定学习者已经深入理解 React,初步理解 Flux,此时学习 Redux。
2.4.1 带着目标阅读
阅读是必不可少的,至少我要知道此技术提出什么理念解决什么问题。就如上一段所说,我们不可能从头读而是带着知识经验结合目标阅读。学习新知识首先读的一定是官方文档的 getting start,以及文档中的 demo,了解清楚这个知识属于哪一个领域,解决什么问题,背后的理念大概是什么。带着这几个问题读一遍官方的介绍,切记带着目标读,让资料跟着你走,而不是一上来就看怎么 install,或者深入细节。显然 Redux 介绍一上来就说了提供一个可预测的全局 state 管理数据。解决的问题依然是 data-view-action,只不过每个过程总线化管理。接着往下看一点案例结合我们的经验不难理解 Redux 是侵入了 React 本身的 props,用外层的 store 接管了 this.state,setState 方法变成了需要触发被 dispatch bind 的 action,而后 reducer 接收而后改变了 state 而后被 connect 的订阅者听到影响 props 改变下一版数据的试图。如果你对 React 本身很熟悉,这些在初步阅读 Redux 官方文档以及 demo 的过程就可以体会到。通过知识对比则更清晰,就是把 React 自己的 setState --> this.state --> view,父 state 通过 props 单向往下传的模式,变成了 setState 的过程在外面通过 action-reducer 完成,state 变了则 connect 订阅者会往受体注入 props。这些信息在初步阅读中结合 React 的知识迁移就能大概体会到。最后把心得体会更新到自己的知识树上,哪怕他只是我的联想,未来会被更正。
2.4.2 实践学习
计算机是工科,实践和理论需要并行,互相加深理解。目前对 Redux 初步有点概念了,但是具体怎么实践并没头绪,此时要做的就是玩开源项目并自己做实验。一般选择官方推荐的学习项目,把项目拖下来后做一个分类。比如有的就只是 todolist,为了说明数据流的机制,有的增加了异步事件处理,有的增加了全局数据缓存 feature。记住不要纠结 demo 的功能有多 low,关键是提取技术点,然后结合自己的知识树互相对比学习。项目的学习顺序一定要从越简单开始往难走,越简单越可以单元化的看问题,当你掌握了之后,以这个为基础再去看比他技术点多一点的项目。学习项目中最重要的是,学习写法并分析他的用意,遇到不懂的,立马查补。比如对 ES6 的一些知识不够熟练,看到某个写法有点懵。此时应该立马记下来,看看能不能大概查阅他的意义跳过先看,如果确实是一个重要知识点无法跳过,则必须弄清楚后继续。这里强调实验的重要性,学习别人项目绝不能只看代码,而是自我去做功能变异与代码变异。功能变异是指增减改同类功能。比如他做了一个加法器,那我用同样的方法在下面做一个乘法器,走一遍新 feature 的流程,不会就 debug, diff……代码变异则更关注实现细节,比如你可以换个写法实现某个方法为达到同样的测试结果。
2.4.3 快速深化学习
实践学习基本上是在别人的项目上做实验,是需要忍过去的。因为你还没有开始完成我们这节的目标亲自去做工作。当你确实看了好几个项目,并做过好些实验了,我们可以开始做快速深化学习。这个过程是一个循环,参考理论和别人的项目来写自己的程序。遇到不懂立马中断,回去做实验查资料更新知识树,深化完继续前进。比较痛苦的是,往往一开始你的项目进度非常缓慢,查资料和做实验的实践耗了很久,但是我的经验告诉我,知识的持续翻叠和联想对比很快能让你走出困境。
2.4.4 夯实基础,缓慢递增
这时候你工作的项目已经能应付,确实采用了一种社区推荐的方案重构了你的项目,配上了 Redux,也踩过一些坑,大概体会到它带来的好处与麻烦的地方。此时最容易放松,但是千万不能放松,因为你的理论和判断能力还是很弱,换个业务逻辑也许又无从下手。但是,经过这过程,你对整个知识骨干已经有理解了,对知识关键词也很清晰。这时需要对知识做拓展,和其他知识做关联,补充之前快速学习忽略掉的一些细节知识。这个过程是缓慢的,随着时间越长经验越足积累越深。
3.0 知识迁移
我们把学习知识比做一个叠纸游戏,有的人在不断学习的过程中,只是往上叠纸,那么学习10个知识点也就10层。有的人则是把知识混合,相当于对折了10次,最后哪个人的作品高度高呢?很明显,能把纸做对折的人是压倒性优势。很多知识他是有内在关联的,当我今天听说一个新知识,首先要对这个知识做归类,一般就是属于哪块的知识,解决什么问题,与现有的知识关系是什么,然后产生新的疑问和联想,然后再去循环研究。接下来从解决问题和主动学习两方面讲解一下。
3.1 解决问题
在解决问题时,很多思路并不是这个新知识告诉我的,而是我在其他地方的编程经验告诉我的,于是我很自然的联想到在当前的场景下,是否这个方法是否也会有实现,然后把未知问题做转换。
以前在开发前端时,我会在启动开发项目时做这样的事:
APP=v1 PACKAGE_SERVER=... yarn run dev
其实就是启动时给当前的语句配置环境变量,这样我能在里面能抓到 process.env,然后通过 Webpack DefinePlugin,传递到 JS 里,存放在全局单例 config 中,供其他 module 引用。
但是我们思考一下,如果这里的环境变量非常多,那么处理起来就会很难受,必须借助 Dash 或者一些 Snippets 工具记录。于是迁移一下在写 Ruby 时用到的解决方案,叫 dotenv 他会解析 .env 文件里的环境,在加载时,他自动把 env 灌进去,对里面代码实现无侵入,好处则是我可以把这个 .env 文件 gitignore 掉,然后在本地开发时简单编辑文件切换不同的 API 等编译时环境变量。于是自然而然去搜索 .env in JavaScript 的实现,果然 JS 社区造就有人干了事。于是立马就引过来用解决问题。
这样的例子还很多,比如我在做前端 route 切换动画的时候,我会想的是以前写 iOS 前端时,他有一个切换算法很不错,于是对着 Apple 文档对着用 JS 实现一遍;比如我学习 React,看到一堆生命周期,就觉得非常眼熟,只要你学习过 Android 或者 iOS,生命周期就是最核心最基础的东西,这些知识点都是相通的,可以大把节省你的学习时间;比如在实践 Java 的 Spring 框架时,我也会和 JS 对比着想,了解了动态语言和 Java 这类的区别,比如对权限的表达,对类型的深刻理解等等。
渐渐大家就会发现,各语言的设计思想就是在不断借鉴与融合,对语言和框架的设计我个人始终它觉得是一个哲学问题。大家细心观察,就会发现很多开源项目的 title 后都有一个 inspired by xxx, 这表明它也是受到了其他技术的启发,在自己的项目中利用这些思想,并向原项目致敬。
3.2 主动学习
比如我今天学习垃圾回收(gc)这个知识。对这个知识结点的新增是在学 C 的时候就完成,后来学 Java 垃圾回收机制时增加了知识子节点,并和 C 做对比。最明显的就是 C 里对象所占的内存在程序结束运行之前一直被占用,在明确释放之前不能分配给其它对象;Java 则当没有对象引用指向原先分配给某个对象的内存时,该内存便成为垃圾,这个垃圾能被自动清理。那下一个问题就是 JVM 怎么做自动清理的,自然也就有变量生命周期、清理调度机制的问题。下一个问题就是了解清楚后,我要怎么去节省 gc 开销,比如就会有对象不用时最好显式置为 Null 啊等实践。
这些学习的问题同样会带到 JS 上,我也会担心 JS 啊。后来知道 JS 也是属于自动回收,就自然也有变量生命周期一说。于是就会去思考什么情况变量算不用了,得出函数的执行结束,那怎么算函数执行结束,闭包呢?一路往下想。JS 垃圾回收的调用者是浏览器,目前机制主要是按照固定的时间间隔周期性的执行,但是 IE 早版本就不是这样,用的引用计数法,那么当存在循环依赖就会出现内存泄漏,需要你手动置 null。在知识不断联想和迁移过程中,我就会去思考在 C, Java, Ruby, Python, Go 分别是怎么做的,有什么共同点,我要注意什么。这次分享不对这块深入展开了。
说到这里大家应该深有感触,当我把知识交织在一起,就完成了这个叠纸游戏中的对折,而不只是往上加一层,能迅速了解一个方面的知识,而不是一个点。
4.0 信息获取与筛选
与以往的教科书或视频的学习方式不同,前端开发从开源项目源头迅速传播过来,版本也以天的单位在更新,社区非常年轻,不断涌现新的 issue 与新解决方案。这些知识被整理归纳成册或者教学视频是严重滞后的,我们需要更主动的获取知识并自我归纳整理,本节重点介绍信息的获取与筛选。
4.1 信息获取
对开发而言,信息获取的载体主要包括:
- 社区
- 博客\&文章
- 文献资料、书籍
- 社交
4.1.1 Github(社区典型)
非常感谢 Github 给我们营造了一个很好的技术中心,自然在这里也是检索信息最直接的途径。我们可以利用github的项目搜索,代码搜索等功能,对自己感兴趣的项目进行检索,观察别人是如何实践如何解决问题的。

code search example
issue search example
天下代码一大抄,看你会不会抄,会不会学会不会及时改。Github 上也有丰富的社区资源,会不会寻找到小伙伴一起学习,至关重要。这会在在社区化学习一节中深入讲解。
4.1.2 Google
Google 的重要性似乎大家都明白,但是能用好 Google 的人却很少,会不会找到合适的关键词描述你的问题就是一个难点。在之前讲过的案例中,关键词是随着我对问题的深入,不断抽象成更贴切的描述原子问题的检索词。甚至我从信息结果中看到有价值的信息灵感术语拼接作为关键词再度搜索,这将会是你综合能力的体现。平时在训练时,可以你可以利用迅速它帮助别人,解决各种朋友的问题,你立马就是大神,因为其实身边能用的好 Google,并能迅速总结概括的人真的很少。
4.1.3 Stack Overflow \& Medium \&翻译
问答社区以及精品资料推送站往往也是重要信息渠道,社区提供很多机会让开发者参与问答。尤其在写代码的时候,Stack Overflow 和 Dash 一样必备,可以让我迅速了解其他小伙伴问的同类问题,自己也可以提问。而 Medium、优秀博客则成为主动学习的重要读物。如果你的英语不够好,我们可以试试chrome自带的翻译功能,看了下面两张图,大家是不是可以感慨一下当下的技术翻译组是不是会被google的AI翻译给替代了,只要做简单的梳理就可以很专业,在这个工具足够强大的时代每个人都可以轻松阅读。
原文
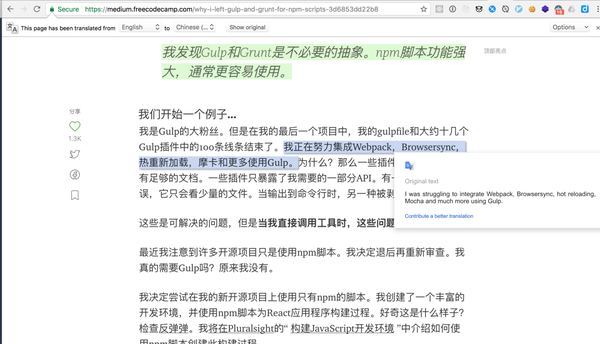
翻译
4.1.4 书籍和文献
书一定是必不可少的,我依然会去泡图书馆、下载电子书。但是读书是有方法的,不一定有时间让你从头看到尾,需要有选择性的阅读,边读边整理。比如我在学函数式编程的时候,我确实已经看明白了社区的案例,也已玩过很多 demo 并自己实验,但是我对函数式思维基础知识和架构的理论知识还不太理解,此时我需要去看一些相关书籍,比如函数式编程思维一书,边看边整理笔记,优化我的知识树,让我弄清楚它。资料来源其实非常多,比如大名鼎鼎的awesome-X系列
awesome-react
awesome-redux
awesome-mobx
.....
几乎想到一个知识点,就可以去搜索关键字 awesome+x然后获取相关学习资料,其中有paper,有document,有book和视频,有知名开源项目,有创作者的blog等。
具体怎么读怎么整理会在后面章节介绍。
4.1.5 社交
社交大家想的最多的就是娱乐聊天,其实这是我几年来最看重的学习方式之一。一个技术之所以能发展起来,对这些技术的贡献者和社区的活跃分子是重重之重,他们经常在关注的,讨论的,往往是这个技术的核心,毕竟他们会比我们更拿捏得准方向。因此我们需要去 follow 一些人,参与一些他们技术讨论聊天室,比如 slack, gitter, discord 之类,在聊天室里多问多听即可迅速成长。平时 follow 的重点则是湾区,硅谷的一些朋友,一些知名大公司开源组织,一些书的作者,一些技术的分享达人,一些技术的重要贡献者,往往这些人也会被整理在 awesome + x 系列中的 who to follow 里。
关注的另一好处在于当我遇到难以解决的问题,我需要向社区求指点。这比我问大学老师或者高价找培训班答疑等靠谱多了,社区有很多小伙伴都会很愿意和你分享他们的知识,有together的感觉之后,很容易进步。
关于参与社区分享 meetup,建议大家可以参加一些高质量的分享小会。一些大会偶尔去一次就行了,它更多是概览和方向,给小白普及知识以及介绍自己的成果居多,很多 google 也能搜到,未必能解决你实际问题,给你思路上的灵感。不过你可以获得一些公司的技术路线。一些小的 meetup 、圆桌问答、技术读书会还是很有价值。比如 aws 的架构师和合作伙伴论坛,我曾经去过几次,基本就是解决问题为主,思路引领为主,我就觉得受益匪浅。这样大家一起就某个具体问题展开讨论碰撞,会对学习直接提供帮助。
最后必须补充一点,国内的技术社区最近萌生了一个现象,大量技术网红大v,自媒体技术人一夜之间如雨后春笋般冒出,似乎我们都在积极的分享技术。这在一定程度确实提高了大家对社区和知识讨论的关注度,确实是一件好事。但是另一方面我也看到了大家的浮躁,以及为“名声”故意做出的一些不应该出现在技术圈的行为,比如恶意刷粉,技术文以及项目的抄袭,言语轻狂跑火车,以及一些粉丝们的无脑跪舔,神化一个技术的极端现象。我很遗憾以前端开发居多。也许有人会觉得这是走捷径上位的方法,这是非常危险的信号,需要引起整个中文社区重视的,不然可以想象未来会被污染成什么样,还会有人好好写代码吗。
4.2 信息的筛选
在上述那么多信息获取方式中,我们已经得到巨量的信息。这可不是好事,信息越多,筛选信息就成为了最重要也是最难的事。我们的思路是寻找搜索项然后做类 SQL 的思维过程。然而这些搜索项的建立是比较难的,他会随着我对一部分信息的理解程度变化而变化。这里我简单讲自己的做法,我会带着不同的目标看待每次的筛选过程,比如我需要有代码 example,我需要时间是比较新的,发布在比较权威的资料站,大家有讨论……
这些表层硬指标可以简单做一层 filter,第二次 filter 则要从我对知识的理解而定,甚至从某些信息上发现这此搜索方向就有问题,那就立马切换。当然如果我确实找到了我要的资料集,接下来要做的就是 map,把每一个子资料中我要的部分 highlight ,加入我自己的想法,同时去掉无关因素,最后则是 reduce,把它汇聚成我要的知识集。
5.0 新形势下的阅读方式
这节让我们深入思考面向未来的阅读方式。
5.1 边读边整理
我们需要有逻辑有目标的去读书,简而言之就是资料跟着你走,而不是你跟着资料走。举个例子我在读函数式编程思维一书的时候,我很清楚我的目标就是了解函数式编程的核心思想、核心概念、各种写法,及解决的问题。于是我在读书的时候也会跟着自己的主线选择要看的内容,当然有时内容也会让我增加预定的主线节点。看技术书,其实和信息的筛选挺像的,不仅仅要读完,更要写完。利用 margin note 这样的工具,我边读边做摘抄,写自己的评论,做思维导图。例如:
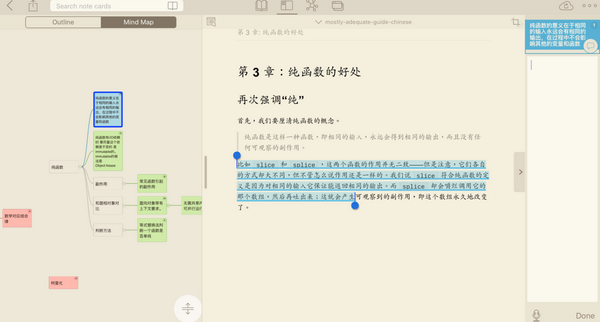
margin-note阅读demo
对于好的资料集,我们还可以利用Flash cards把一个问题做记忆卡片,不断温习。
当然现在,对于网页的内容,比如medium上的知识,我们可以利用 chrome的diigo插件做一个在线annotate,或者利用他保存成PDF然后交给margin note处理
diigo demo
当然,如果是技术书就会有很多实践类内容,更需要做实验,比如书上只是用 Java 语言为例讲解了 curry 的概念,那么我一定会在边上把 JS, Python 的实现补上。看了这些后,有没有买ipad,疯狂买电子书,转换电子书的冲动?
5.2 同时多本书一起读
同时读几本书在以前看来是很难,然而现在对同类书籍用的非常多,比如学习函数式编程的时候,我就同时开了函数式编程思维,JS 函数式编程,Java 函数式编程。然后我对这部分采用敏捷学习法,其实就是对这些我要学的知识树不断做 merge,并关注 diff 和互相的关系。比如,在 Java 函数式编程里提到了范畴学和组合,但是在那本书只是提及并没有深化,于是我去找函数式编程思维和 JS 函数式里面对这块做了解释,那么我就会整理在一起。这样的案例还很多,比如同样搞语法糖,我在学习 ES6 语法时看到了 arrow function,我立马去找 Coffee Script,因为在 Coffee 里有胖箭头和瘦箭头的区别,主要就是 bind 不 bind this 的区别,而 ES 只有胖箭头,当我在一个闭包里要创建非 bind this 的方法还得去用老方法。

margin note 书籍分屏
6.0 社区化学习
之前我有提到过社区的重要性,本节更深入的讲解一下。
6.1 你会用 Github 么
社区并不仅仅是被动解决问题,更是主动学习的好地方。
6.1.1 Github 项目生命周期
简单的说,一个新的 feature 会经历:
- Issue 被提出,大家参与讨论;
- Issue 被分配者或其它开发者向约定分支提 PR,并指向这个 issue;
- 之后大家都可以 review PR,对其中的代码做疑问;
- 随后有权限的 core 开发者则可以确定是否合并;
- 合并完后看放在哪个 release 发布;
- 作为管理者,则会通过 label 排好 issue 的优先级,并建立好 milestone,然后利用 kanban 管理进度。一旦有人提了 PR 需要去审阅他的功能,代码风格,代码文档,代码测试,并关注一下 ci 反馈的结果,此时也会在 issue 下面和大家做更深入的讨论。
- 最后,当一个 milestone 包含的 issue 都被 kill 掉了,就会新建 release 分支,然后在上面做一些 Bug fix,改版本号,写 changelog,最后发布到 master。
6.1.2 学习
这些周期中,我们主要参与的是:
- 对 issue 的深入讨论
- 对项目的直接代码贡献
- 代码的 review
Review 不仅仅只是纠错,更是一种学习。我们可以了解别人的写法用意和实现方式,我经常在社区 review 别人的代码,很多时候只是提问 + 学习,效果绝对比自己读源码好得多,毕竟这里有大家一起讨论。
Issue 则是让我知道大家会遇到哪些问题,现在是怎么解决的,往往能学到很多知识。每个 Issue 的建立初衷一般都是为了得到 PR 改善这个问题,当然很多问题不一定需要 PR 就被别人解决了或者被关联的 Issue一起解决。
举个例子,比如我在学习 React 的 createElement(null) 在 DOM 中的表现,当然我可以做实验,我也会去 React 的 Github 搜一下 release log和相关的issue,于是我发现在15.0.0的版本中提到。
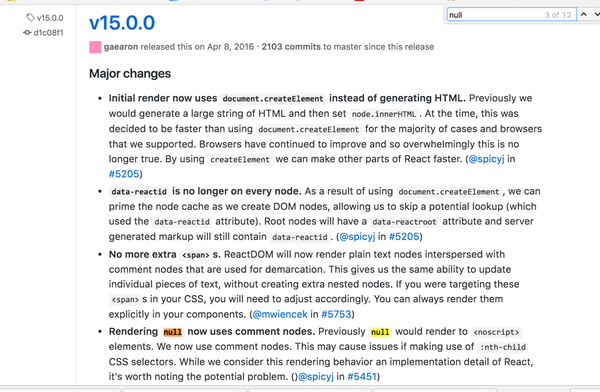
github pr example
于是我追溯进去看了一下 PR 和大家对此的讨论 [Use comment nodes for empty components],通过它我又知道了这个 issue 的历史,曾经 chenglou 同学在解决 [React.EmptyComponent (NullComponent\?)] 这个 issue 是通过返回\元素,但是这导致了 nest dom 处理时的兼容性问题,于是15.0.0版本返回<!-- react-empty: 1 -->这样的注释节点更 make sense。搞清楚了理论后,我就自己做实验,确实发现如此。为了更进一步学习,我去看这个 PR 的 [file changes],看看人家是怎么实现的,有没有我能学习的。最后把这些知识点 persist 进我的知识树。有的同学问我要不要去啃源码,其实对着源码啃是很难的,也很枯燥。但是对着 issue 以及 PR 搭配我们的 debug 工具去啃,边实验边参与讨论,才是社区化敏捷学习的精髓。
对于代码 review 目前除了我们可以在 github 参与review别人的代码,我们也可以在stack overflow review中提交自己的代码给别人 review 或者 review 别人的代码。通过对代码和其实现的预期的探讨,就能碰撞出智慧的火花,互相取长补短。
6.2 你会聊天么
社区除了 Github 阵营外,团队有比较知名的 Slack, Gitter, Discord 甚至 Reddit 等讨论区。个人则是 Twitter 和 Facebook 以及自己的博客居多。往往我们经常在用的技术都有自己的官方讨论区。
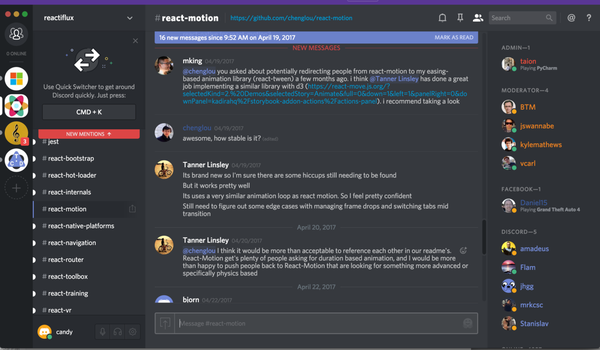
reactiflux facebook 官方技术chat社区
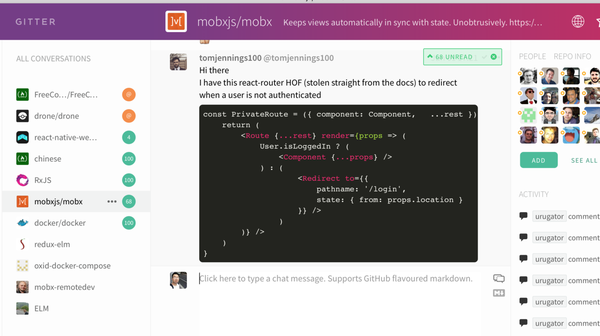
mobx Gitter社区
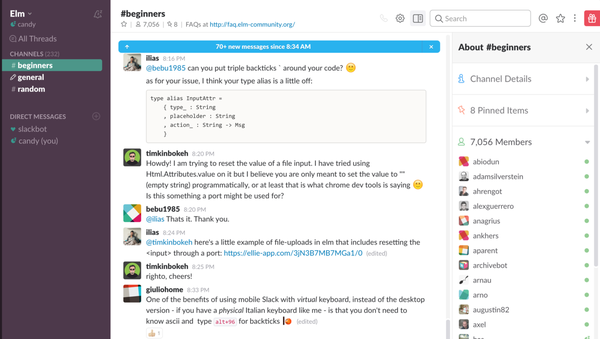
elm slack社区
比如上图中看到 react-motion 的大神 chenglou 正在回答大家的使用问题,并且我们仔细看左侧的列表,会发现 React 经常遇到的问题都有相应的解决方案。于是还等什么,赶快敏捷学习更新你的知识树吧,聪明的人搜搜聊天记录就能学到不少!当然这里不得不提,聊天是有礼仪的,我看到 Gitter 上一些国人开发者有素质低下的沟通表现表示很气愤,这里的技巧有机会再给大家详细分享。
6.3 你知道 follow 么
有的同学很迷茫我每天该看什么,结果就看知乎的心灵鸡汤,或者是脉脉里无聊的工资的讨论。真正需要看的并没看,只是捧着技术厕所读物在那边反复咀嚼,还觉得是金子。那么我们该看什么?信息推送站比较知名的是 Medium, Hacknoon 等,个人部分则 follow 那些大神的 Twitter 就好。这里 RSS 阅读器就非常重要的,我习惯用 Reeder, Chrome 的话用 Panda,用他们订阅一些感兴趣的 feed,包括 Medium, Egghead,掘金以及一些 follow 的朋友的博客。

chrome panda tab example
reeder 订阅example
7.0 工具\&实验田
7.1 工具
对工具的依赖其实很多同行有自己的看法,我是一个比较务实的人,我觉得工具就是为了提升效率的,多用也没什么问题。
必备开发辅助工具比如 Dash,帮我快速的查询 API 以及使用 Snippet;SnippetsLab,对经常用的代码片段做一个 notes 管理;Alfred workflow 之类,帮我做一些自动化的操作; Kaleidoscope 做一个文件 diff 工具;marginnote, xmind,freshcard, lucidchat 等学习绘图工具;还有 Chrome 上的一堆插件等等。
比如,我经常会用 kaleidoscope 做 diff,之前我在逆向一个编辑软件的工程文件格式时,我就会去操作这个软件,然后对每一个版本的 snapshot 做 diff,以此观测该软件的算法,我在分析 ci 报错时,我也会拿成功和不成功的两份 log 做 diff,判断出现问题的地方。
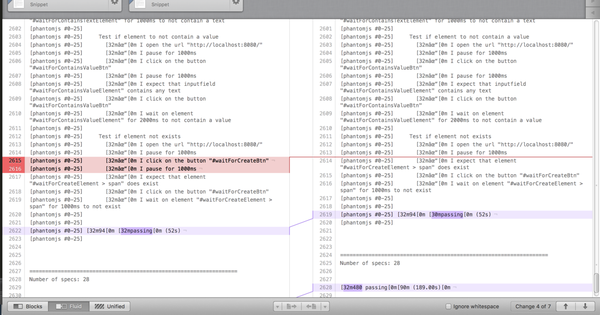
前端测试ci成功-失败对比
比如,我经常会用 Dash 的 snippets 做一些 Shell 命令的快捷操作。

dash snippets demo
上图中,我可以简单在shell里打 delete docker container,就可以给我反馈这一长串删无效 container 的方法。
同样,我使用 SnippetsLab可以收入经常用但容易忘的一些snippets
Snippets Demo
chrome插件部分就举一个常用的例子吧,开发前端,经常会遇到跨域问题,此时我们可以简单的用mod header插件修改request和response的header。
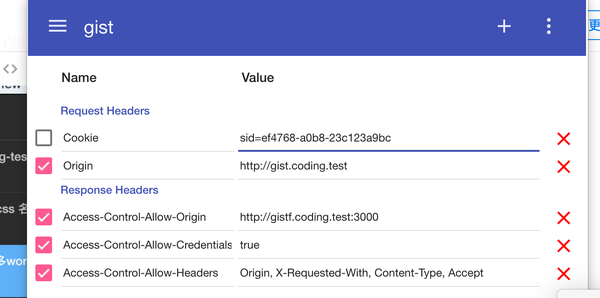
主力要注意的是,插件用多了就还需要一个管理插件的插件,管理好每个插件每个profile。
chrome plugin demo
这篇分享并不是工具篇就不再深入,具体还有哪些可以去看 awesome-mac,我只是让大家知道工具在敏捷学习中的意义。
7.2 实验田
当我脑海中有一个技术思维或者从资料中获得一些信息,我并不是很确定他是否正确,我需要快速的隔离问题并得到答案。于是我会利用工具建立自己的实验田,实验环境是隔离于工程并 mock 完需要的上下文或者把工程 mirror 后作为上下文变成一个独立容器,或者利用 online 的实验田,例如 codepen, 在上面搭配测试写实验。例如当我在做移除 react-auth-wrapper 地址栏的 redirect 参数时。我把问题归结于 hack 掉他的 push 配置,写一个 util function,接受一个 url 参数: http://www.coding.net\?aa=1\&redirect=xxx...然后丢掉 redirect 的信息并返回。这些就可以隔离在实验田做完,写完测试,然后把正确结果打 patch 丢回自己分支。在做实验或者单元化开发的过程中有两个核心点。1. 问题的模型抽象与上下文mock 2.关键在于“creator should be able to see what they're doing immediately”理念。对于第二点很重要,编程应该是创造,创造你就需要更多思路,思路来源及时的看各种反馈,最快时间判断思路是否可行是否符合预期,并最快时间切换思路。这里提供这个观点的一个介绍 BRET VICTOR – INVENTING ON PRINCIPLE

算法实验田
这是一个我经常用的算法实验田,我们可以在上面配置常用差不多的近似算法,并第一时间根据图获得灵感
regex实验田
bash 实验田
8.0 时间管理
敏捷学习的关键词是敏捷,要求在短时间内掌握知识,解决各类问题,同时不断加深知识点的深度和维度。这其中就需要对时间做管理。如果我看一个资料太陷入细节,一层一层往里追溯,最终的结果就是在那一个问题耗时太长,工作任务完不成了。于是除了聪明的学习外,我们还要管理自己、约束自己的学习。比较推荐的做法是使用 Omini Focus,学习一下 GTD 时间管理法。对要做的知识学习事件做一个整理,写进 inbox ,并对每一个事项做一些配置,包括轻重缓急,需要用到的资源、上下文,需要协作与否等。
9.0 画图与做题
9.1 画图
第一版中我没有提这块。后来和读者交流下来,觉得这快必须加上。作为程序员,必须有对问题的抽象和画图打草稿的能力,这里的画图指的是对自己的思路做整理,对代码逻辑做整理。最简单的例子就是UML图,当面向对象编程,我们对代码需要做一定程度的分析,了解设计模式,清楚的知道自己在做什么。现在非常好的工具能帮助你,比如starUML,process on,lucidchat,以及我最喜欢用的plantuml,除了它用简洁的类markdown语言表达UML之外,他还允许你定制UML方言,当然就可以用它定制一套react的UML规则,见plantuml in react

react uml demo
当然很多时候,函数式编程我们可能更需要 viskell函数式类图的帮助。

image.png
有时,我们也要学会用更自然的语言来表达需求,比如前端开发是的behave driven,也就是用户故事主导,所以一般用Gherkin syntax来表达用户故事和测试。

一个feature的demo
9.2 做题
刷题理论相信很多应聘者早已烂熟于心,以至于面试前不刷(背)几遍leetcode不好意思出门,当然这个是有必要的,至少带着一个我是准备过的诚意。类似的网站挺多的,做得比较好的还有kaggle,lintcode等。当然平时学习时,做题则是为了对一个课题更深入的理解,其实就是制造问题和解决问题的过程。我们也许应该做的是对问题的归类,并发现其中的规律自我出题自我解决。如果有朋友,则可以互相出题互相解决。利用互联网,我们也可以对一个issue查询别人对他的各种问题和解答,并积极参与讨论。
10 总结
新形势下我们需要更敏捷的学习, 利用一切资源快速更新自己的知识树,为了达到这点我们就必须要学会知识迁移能力,用对折的方式交织性学习而不是孤立的往上铺纸。新形势下,我们需要利用好新媒体、新搜索工具以及社区,在得到大量信息后要学会筛选和整理。为了更深入的理解原理,我们依然需要读书,只不过读书应该带着目的读,边读边整理,建议多本书对比着读,对比着整理。当我们已经整理了很多知识,要积极参与社区的活动,去和他人分享自己的实践,同时也从他人那边获取有价值的信息。得到各类信息后,需要在实践中学习和检验,我们时不时需要在实验田中做实验,检验某一个方案是否可行,把可行的有测试保障的代码很自信的搬回我们的仓库。这一系列过程,我们都需要敏捷,必须对每个学习过程做好时间管控,不能深陷其中耗时太久。
关于语言能力,由于当下技术大多是从开源英文社区直接传递过来,以上所有的步骤都离不开英语,所以对语言的基本阅读能力是敏捷学习的前提条件。如果你的语言不是特别好,我们也可以借助chrome中自带的google强大的翻译功能辅助帮助你理解,目前google的翻译越来越厉害了。
关于技术学习,并不能只学 JS,其他的编程语言,都需要学习和实践,只是以一个语言为精,这样才能更好的做知识迁移,遇到新知识才会有联想有感觉。前端有太多的坑,需要一直跟进社区,保持重构,以及创造各种适合自己的实践。别人的实践很多情况只适合他们的业务场景并不具备通用意义,前端的库都只是依赖包,也就是一些工具,提供了一些api解决特定的问题,可以说大家每个项目都能诞生几个库。所以用或不用,用部分然后自己改还是用全部,怎么组合,还是需要大家根据自己的业务需求而定,不过优秀的开源项目给我们提供了很多实践参考,让我们思路更开阔。关键还是这面向未来的敏捷学习能力让你任何时候立于不败之地。
饥人谷一直致力于培养有灵魂的编程者,打造专业有爱的国内前端技术圈子。如造梦师一般帮助近千名不甘寂寞的追梦人把编程梦变为现实,他们以饥人谷为起点,足迹遍布包括facebook、阿里巴巴、百度、网易、京东、今日头条、大众美团、饿了么、ofo在内的国内外大小企业。 了解培训课程:加微信 xiedaimala03,官网:https://jirengu.com
{kind=link}
本文作者:饥人谷方应杭老师